Good Practices for Enterprise Integrations over the Azure Service Bus
Integrating systems over a good messaging infrastructure has many benefits if done right. Some of these are system/network decoupling and platform agnosticism, independent scalability, high reliability, spike protection, a central place to keep an eye on your integrations and more depending on your situation.
Many of these benefits are vast topics on their own. But the point of this article is to go over some of the pitfalls when implementing large-scale integrations over a messaging infrastructure and guidelines for avoiding them.
These are based on my learning from a recent project which involved improving a client’s existing integration between 5+ large systems. While the messaging infrastructure in use was the Azure Service Bus, I believe most of these points apply to all other message-based integrations and service buses.
1. Don’t roll your own
 Don’t re-invent the wheel.
Don’t re-invent the wheel.
Not rolling your own should really be no-brainer in all projects, yet you still see it unnecessarily done more often than you should.
Unless your aim is to provide a competing solution that works better than what’s available and you have the resources to maintain it, you will get it wrong, miss edge cases, and it will eventually cost you more as your efforts are diverted from delivering business value to maintaining your custom solution.
So stand on the shoulder of giants as much as you can by using tried and tested infrastructure that’s already available.
2. Don’t bypass your messaging infrastructure
This is closely related to the previous point and includes plugging in your own service bus-esque solutions alongside a proper infrastructure like the Azure Service Bus, for example, storing messages in a database table for later processing.
One of the major initial issues I identified with the client’s integration, was that to avoid queues getting full, they were retrieving messages from the queues, storing them in an MSSQL database and doing the real processing from there. This had introduced a big flaw in the design, losing out on many benefits that came with ASB:
-
Proper locking of the message when it’s being processed, to prevent duplicate processing. Implementing your own locking mechanism on a database table is complex, error-prone and can easily cause dead-lock situations.
-
Scaling and performance. Even if you get the locking right, it won’t be anywhere near as performant as a proper message queue for high-traffic scenarios. You’ll have a high-write, high-read situation (a lot of messages coming in and a lot of polling) which is very hard to optimize a SQL database table for.
-
Availability and reliability. A good messaging platform like ASB, is highly available and redundantly stores your data.
-
Filtering, dead lettering, automatic expiry and a myriad of other features that come with ASB.
This would lead you to the pitfall #1 from above: in order to get it right, they had to essentially roll their own messaging infrastructure, so they ended up with two problems instead of solving the first one.
Treat the root problem, not the symptom.
 ‘What was the original problem you were trying to fix?’ ‘Well, I noticed one of the tools I was using had an inefficiency that was wasting my time.’
‘What was the original problem you were trying to fix?’ ‘Well, I noticed one of the tools I was using had an inefficiency that was wasting my time.’
3. Use shared topics and a pub-sub pattern instead of queues
Imagine the scenario of updating customer contact details in a CRM system which should be reflected in the sales system. There’s only two systems, so it might be tempting to do something like this:
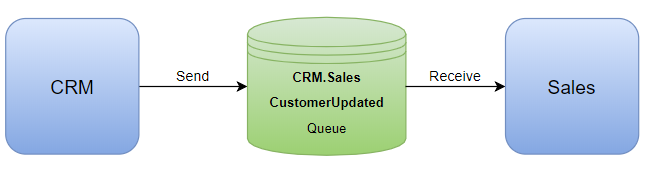 An exclusive topic/queue for sending a single system’s customer update messages, effectively creating a point-to-point integration.
An exclusive topic/queue for sending a single system’s customer update messages, effectively creating a point-to-point integration.
This might look fine if you’re only starting with a couple systems, however not going down this route is critical for future maintainability.
Let’s say after some time, the business needs a third legacy system – one that drives many other parts of the business – integrated as well:
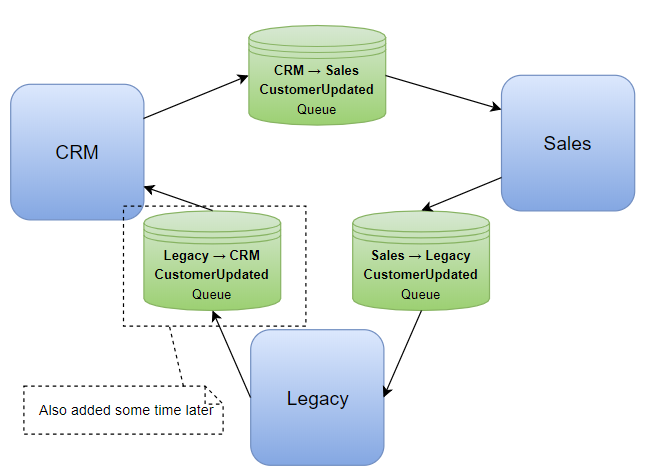 Keep it simple?
Keep it simple?
There’s several problems with the above:
-
Single points of failure. Each of the systems being slow or unavailable breaks the link and the data no longer flows to the next system. This actually caused one of the client’s main systems to have data that was weeks old until the faulty system was properly fixed and processed its backlog of messages.
-
If, some time later, you add a third integration between the legacy system and CRM like the diagram, all of a sudden you have inadvertently created an integration between all of the systems by forming a circle which may not have been your intention. It also becomes much more difficult to reliably stop infinite loops from happening between all the systems involved where one message keeps going round and round. This can result in invalid data and even more resources being wasted. More on this below about having a mechanism to stop infinite message loops.
If you want to have redundancy, you’ll end up having to integrate each system with all the other ones:
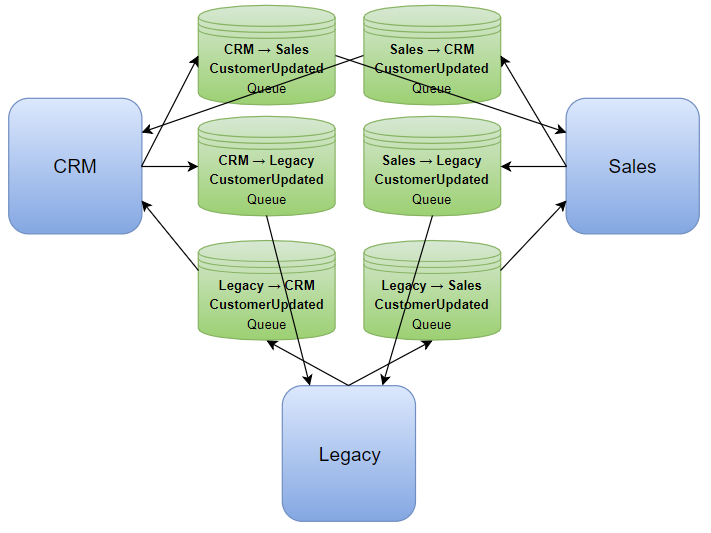 Fancy some spaghetti?
Fancy some spaghetti?
With only 3 systems and one simple message, this is already looking like a mess. As you add more systems and integrations, it becomes exponentially costlier and harder to develop and maintain.
There are many flavours to these point-to-point integrations and each come with a similar set of problems.
A much better approach that addresses most of the above issues and is easily maintainable, is a shared topic that all participating systems publish and subscribe to:
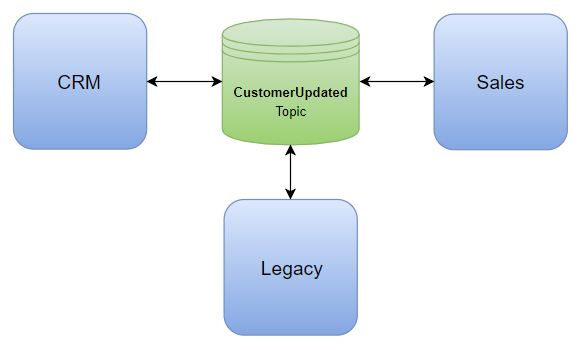 The publishers don’t have to know about the other systems. Any interested system can subscribe to the topic, effectively getting its own queue.
The publishers don’t have to know about the other systems. Any interested system can subscribe to the topic, effectively getting its own queue.
By using this approach, you further decouple the systems, keep it extensible for plugging new systems and keep complexity and maintenance costs linear. If subscribing systems need to know where a message originated from, that can be included in a standard message body format, or better yet, message properties as they can drive filters and actions.
4. Be mindful of loops – subscribers shouldn’t republish
It’s very easy to cause infinite loops that can wreak havoc on all the systems involved. From the above example, it can easily happen if each system received a message from the topic, updates a customer and as a result republishes a CustomerUpdated message back to the topic.
One solution to this problem that works with the above pub-sub model, is that a system’s action based on a message received from the topic, shouldn’t cause the same message to be republished back to the topic.
5. Include domain event timestamps in messages
Each message should have a domain event timestamp. I’m not referring to the one that is automatically stamped on messages by the service bus, but one included by your system in the message. The timestamp should describe when the event the message describes happened within that system. e.g., you care about when a customer updated their details in a system, not when the message was published and not when another system finally gets around to processing it.
This provides a means for other systems to not act based on outdated data. e.g. it’s possible that by the time a subscribing system receives a CustomerUpdated message, it’s already applied a more recent update. A simple timestamp check can prevent the more recent data from being overwritten.
While you’re at it, make that timestamp a UTC one – or better yet, use a type that unambiguously represents an instant, like DateTimeOffset – so you don’t run into time zone conversion and datetime arithmetic issues. You only care about the instant when something happened, not the local time, and a UTC datetime simply represents that.
6. Messages should be the single source of truth
 ‘And the whole setup is just a trap to capture escaping logicians. None of the doors actually lead out.’
‘And the whole setup is just a trap to capture escaping logicians. None of the doors actually lead out.’
All necessary information from the publishing system should be self-contained in each published message. That means all the information the subscribing systems need to be able to act on the message.
A simple scenario of how breaking this pattern could cause problems:
-
The CRM system publishes a CustomerUpdated message that only states a specific customer’s details has been updated, without including the details.
-
The Sales system makes a call to the CRM API to retrieve the details.
Problems:
-
There needs to be a direct means of communication between the two systems, whereas before they only needed to communicate with the messaging infrastructure. This takes away system and network decoupling, one of the major benefits of using a service bus.
-
By the time the message is processed by Sales, the CRM API might not even be available.
-
It puts additional load on the CRM system since its API would need to be called for each message.
-
By the time the message is processed by Sales, the customer details may have been changed again. If the Sales system’s action was dependent on the historical data at the time of the original event, such as auditing, it is going to retrieve inconsistent data.
So keep and treat messages as the single source of truth. On the other hand, don’t include unnecessary information and keep them lightweight to make the most of your topic space.
7. Have naming conventions for topics and subscriptions
Each topic and subscription following a naming convention brings many monitoring and troubleshooting upsides:
-
As the integrations within the service bus namespace grow it remains easy to find the target topic and subscription.
-
You can see what’s going on in your service bus namespace more easily when using an external tool like the Service Bus Explorer.
-
It could potentially drive an automatic monitoring tool that can visualize all the integrations and the flow of data between various systems.
An example of such a convention could be:
| Topic Name |
|---|
CustomerContactDetailsUpdated |
| Topic Subscription Names |
|---|
CRM |
Sales |
Legacy |
Like most conventions, the value mainly comes from there being one, rather than the convention per se.
8. Have proper logging and monitoring to quickly identify and deal with issues
Integrations, once in place, shouldn’t just become part of a black box that’s your service bus.
It is crucial to have proper logging and instrumentation and monitoring on top of those in place, to be notified of irregularities as soon as possible. You should have automatic alarm bells for at least the following:
-
A subscription’s incoming rate becomes consistently higher than its processing rate. This should be fine for short periods of time e.g. traffic spikes. However if it continues your topic would eventually get full.
-
A topic’s used space is consistently increasing.
-
A subscription’s dead-letter queue message count is consistently increasing.
The above are closely related and are usually a sign that a subscribing system is having issues with processing messages. These issues need to be dealt with ASAP. Depending on how the publishing systems can cope with the topic they’re publishing to being full, it could also lead to problems in those systems. For the client, this accumulated a backlog of failed tasks in a publishing system that was limited and hosted externally. It was hopelessly retrying over and over, unnecessarily using significant resources which affected other parts of the system such as delays in sending important marketing material.
As a last resort, to stop the topic from getting full, you could set up forwarding to redirect messages for the problematic system to a different backup topic subscription or queue until the problem is resolved. Just don’t move them to a database.
Azure Monitor can help here. Having structured logging of important information to a centralized logging server such as Seq could also be beneficial, however, be careful not to create a lot of noise by logging the world.
9. Don’t forget the dead-letter queue
All queues and topic subscriptions automatically come with a supplementary sub-queue, called the dead-letter queue (DLQ). Messages can end up here for a number of reasons:
-
By the engine itself as a result of your messaging entity configurations, e.g. automatically dead-lettering expired messages or filtering evaluation errors.
-
By the engine itself as messages exceeds maximum delivery count – which is 10 by default. For example, your subscriber receives the message, but fails to process it due to an exception.
-
By the subscriber’s explicit request in message processing code.
See here for a complete list and their details.
These dead-letter queues contribute to the overall used space of the topic, so you should keep an eye on them, using your monitoring tools, and empty them regularly via either resubmitting them if they were due to transient errors, or discard them if they were poison messages.
10. Performance is not just a nice-to-have
Having performant message processors ensures your integrations run smoothly and can withstand traffic spikes without your topics getting full. Here are some tips that can increase performance dramatically:
-
Use AMQP and avoid HTTP polling. This should be the default if you’re using the new .NET Standard Service Bus Client library, you can read about the benefits here. Don’t use the old library – most of the documentation around still point to that.
-
Use the asynchronous callback-based message pump API. Sending/receiving messages to/from the message broker is an inherently IO based asynchronous operation – you shouldn’t hold up threads for them.
-
Process messages concurrently. Many programmers shy away from writing concurrent code, as it is more complex and error prone. That’s usually a good approach, however the free lunch has long been over, and this is one of the scenarios where having concurrent code really shines. Concurrent code doesn’t mean you have to do unnecessary multithreading. If you use the asynchronous APIs and leverage truly async code where possible, even a single thread can accomplish orders of magnitude more. This needs to be accompanied by proper asynchronous synchronization so you don’t, for example, process two messages for the same customer simultaneously.
-
Keep connections to the service bus alive (i.e. the clients) and don’t recreate them as that’s expensive. They are designed to be kept alive and reused.
-
Leverage prefetching with a message lock duration that’s tweaked based on message processing times. When using the default lock expiration of 60 seconds, Microsoft recommends 20 times the maximum processing rate of your subscriber. e.g. if the subscriber processes 10 messages per second the prefetch count could be
10 x 20 = 200. The idea is to prefetch comfortably below the number of messages your subscriber can process, so they aren’t expired by the time it gets around to processing them. You can read more about that here. -
Use partitioned topics. One of their biggest benefits is they can go up to 80GBs in size compared to just 5GBs for unpartitioned ones. That can give you a lot more time to deal with issues explained above and you almost never need to worry about them getting full. But they also have better throughput, performance and reliability. There’s really no good reason for not using them.
By combining the above approaches, I improved the processing time on a critical subscription for the client from ~15 seconds to ~3 seconds per message and the message processing rate per hour from ~240 to ~12000.
11. Have message versioning and remain backward compatible
It’s only a matter of when, not if, that your messages need to be changed. To make moving forward easier and seamless, have a message versioning strategy to start with and make those changes in a backward compatible way.
Prepare yourself for the situation that different subscriptions of a single topic contain different message versions. This allows subscribers to be upgraded at their own pace, while not blocking those that can process the new version.
Old message versions can ultimately be retired when all subscribers are upgraded.
12. Have idempotent subscribers
Even with other measures in place such as duplicate detection. It’s highly likely that your subscriber receives the same message twice. For example, this happens when during the time a subscriber is processing a message, the message’s lock expires and it is released back to the subscription queue. So you have to make sure your subscribers process messages idempotently. This can be achieved via various mechanisms depending on your circumstance, but checking against message timestamps or unique message IDs can be a simple effective measure.
In conclusion, service buses, like any other tool in our toolbox, can be misused, perhaps more easily than some of the others, which has led to many hating them. But they are powerful and very beneficial in the right situation. Following the above guidelines should help you build a solid foundation for large-scale integrations over service buses and not end up with huge improvement costs – because changing upstream design costs exponentially more downstream.

I'm a seasoned software consultant and technologist based in Brisbane, Australia. I've been helping businesses reach their digital ambitions in the fast-paced tech world for about 15 years.
With expertise in people leadership, software architecture and craftsmanship, the Microsoft ecosystem, web technologies, C#, ASP.NET, and Azure, I team up with organisation leaders to bring their visions to life. My passion lies in making a positive impact through technology.
Outside of my profession, you can catch me diving into self-development, breathwork, fitness, travelling, fishing, camping and making random noises with the flamenco guitar.